Jensen Huang isn’t just selling a faster chip — he’s trying to rewrite 40 years of computing history. Here is why the RTX Spark superchip’s architecture changes everything.
The tech keynote has become a reliable genre unto itself. Stage lights. A charismatic CEO. Benchmarks against last year’s model. A percentage improvement that sounds large but lands vaguely. Applause. Everyone files out and waits for the next one.
What Jensen Huang did at Computex 2026 in Taipei on June 1st was something structurally different. The numbers were there — they always are — but what he was actually announcing was a philosophical break. Not just a faster chip but a different theory of what a personal computer is for. The question of what makes the Nvidia RTX Spark different isn’t answered by its specs sheet. It’s answered by asking what’s wrong with the machine you’re currently using.
The Bottleneck We Agreed Not to Talk About
For roughly four decades, the standard PC has followed the same basic logic. A CPU — built on Intel’s x86 instruction set architecture, first sketched out in the late 1970s — handles the computer’s general reasoning. A separate GPU handles graphics and, increasingly, AI workloads. These two chips sit in different parts of your machine, connected by a bus, each managing their own pool of memory.
This arrangement worked fine for the tasks PCs were built to do. Writing documents. Running applications. Playing games. The data loads were manageable, the bottlenecks tolerable.
But AI inference — the kind of real-time reasoning that modern language models perform — is a fundamentally different class of workload. A large language model operating at its full capacity doesn’t move a little data quickly. It moves enormous amounts of data, constantly, in patterns that punish the physical distance between separate memory pools. When your GPU needs to pull data from its own VRAM and cross-reference something from the CPU’s system memory, that gap matters. At scale, it matters a lot.
Traditional PCs require users to launch and type into applications, while the fundamental hardware structure was never built for conversational, real-time reasoning. The result is that genuinely capable local AI — the kind that can reason through complex tasks rather than offering predictive autocomplete — has remained almost entirely a cloud phenomenon. Your query leaves your machine, travels to a data center, gets processed by server racks drawing industrial-scale power, and returns. The laptop in front of you just sends and receives. It isn’t doing the thinking.
That’s the quiet embarrassment the industry accepted. Until now.
Two Chefs, One Prep Table
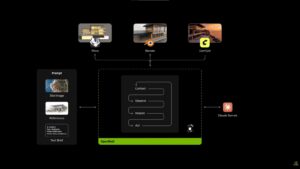
Co-developed with MediaTek and Microsoft, the RTX Spark is an Arm-based system-on-chip that integrates a 20-core Grace CPU, a Blackwell-architecture GPU with 6,144 CUDA cores, and up to 128GB of coherent unified memory on TSMC’s 3nm node. That phrase — unified memory — is the one worth sitting with, because it’s where the design philosophy lives.
In a conventional laptop, the CPU and GPU each manage their own memory pools. Shuttling data between them creates friction; the hardware equivalent of two chefs working in separate kitchens who have to physically walk ingredients across a restaurant every time they collaborate. The RTX Spark removes that walk entirely. The CPU and GPU share one pool — a console and Apple-Silicon-style design brought to Windows — where both can access data simultaneously without transfer overhead.
The practical consequence is significant. According to Nvidia, the platform can run AI models with up to 120 billion parameters and context windows reaching one million tokens — locally, on-device, without a cloud connection. To put that number in perspective: 120 billion parameters is roughly comparable to the scale of frontier AI systems that, until very recently, required entire server clusters to run. The RTX Spark is proposing to do this from your lap, on battery power, with no subscription required.
The chip delivers 1 petaflop of AI performance — roughly 1,000 TOPS — compared to Apple’s 38 TOPS Neural Engine. The competitive landscape is shifting fast, and Nvidia is positioning the Spark as the raw-power answer to Apple Silicon’s elegant efficiency. Different philosophy, different audience. Apple optimized for seamlessness. Nvidia is optimizing for sheer local intelligence
Nvidia’s Quiet Attack on the Cloud
As significant as Nvidia has become to the tech industry, its entire run-up in recent years has been tied to the data center. The RTX Spark changes that calculus in ways that extend well beyond the PC market.
Cloud AI runs on Nvidia GPUs. The data centers powering ChatGPT, Claude, Gemini, and every other frontier model are packed with Nvidia silicon. In a narrow sense, a powerful local AI chip competes with Nvidia’s own cloud business. In the broader sense Huang is playing, it doesn’t matter — because whoever owns the hardware layer controls the compute, whether it lives in a data center or under someone’s desk.
But the threat to pure-play cloud AI providers is real. The commercial logic of subscription-based AI depends heavily on the assumption that your hardware can’t do this locally. Strip that assumption away and the value proposition shifts. Privacy, latency, and cost all swing in favor of the local machine. Running 120-billion-parameter models completely offline and securely on-device isn’t just a performance story — it’s a privacy story. In an era of growing data sovereignty concerns, that matters to enterprises and individuals alike.
Nvidia’s announcement caused shares of AMD, Intel, and Qualcomm to fall while its own stock rose — a market reaction that captured the threat’s scope. Intel and AMD lose because x86 dominance becomes less relevant. Qualcomm loses because its Snapdragon X2, the previous Arm-on-Windows leader, now has a formidable rival with a deeper AI ecosystem. The cloud providers weren’t on the stock ticker, but they felt it.
Old Plumbing, New Engine
The RTX Spark brings together 30 years of Nvidia innovation — CUDA, RTX, DLSS, TensorRT, and the rest — into slim Windows laptops and compact ultra-efficient desktop PCs. That software ecosystem is arguably as important as the silicon. Apple built its M-series advantage partly on hardware efficiency and partly on a tightly controlled software stack. Nvidia’s CUDA platform is the dominant environment for AI development globally — the language researchers and engineers write in when they build the models that run on server clusters. Moving that ecosystem to a consumer device is a significant unlock.
The full picture of what Huang announced at Computex 2026 is this: a machine that can think server-grade thoughts without a server. That doesn’t require a cloud subscription to do serious AI work. That treats local processing as a feature rather than a compromise.
Whether the RTX Spark delivers on all of this at launch is an open question — early concerns around software compatibility for Windows on Arm and pricing remain valid considerations for anyone thinking about adoption. The architecture is genuinely impressive; the ecosystem gaps are real.
But Huang’s argument isn’t that the Spark is perfect today. His argument is that this is the direction of travel, and that forcing AI to run on hardware designed for clicking apps is roughly like trying to stream video over a dial-up connection. The connection works. It just wasn’t built for this.